
Exploring Data Architectures: From Warehouse to Lakehouse with Apache Iceberg


Introduction
Data management is a critical aspect of the Machine Learning (ML) lifecycle, often underestimated in its complexity. As a software engineer with experience in traditional data storage solutions, I've recently delved into the world of data architectures specifically designed for Analytics and ML workloads. In my previous job, I worked closely with the data platform team but mostly to ensure that the ML team has access to the required data for training purposes. While most of the technologies in this space have been around for a while, this is my first time diving into some of them. For a recent project, I was evaluating the use of Apache Iceberg for managing large-scale data analytics. In this article, I'll share my insights into various data storage architectures, including Data Warehouses, Data Lakes, and the Data Lakehouse. I'll then discuss a practical implementation of a Data Lakehouse using Apache Iceberg and the lessons learned along the way.
Data Storage/Management Architectures
Data Warehouse
A Data Warehouse is a centralized repository designed for storing, managing, and analyzing large volumes of structured data. It consolidates data from multiple sources, transforming it into a consistent format for complex queries and business intelligence (BI) purposes, enabling data-driven decision-making across an organization. Some of the drawbacks include, support for structured data only, data locked in with a vendor specific system, and the increase in costs with increased workloads, as it translates to increase in both storage and compute costs. Examples: Amazon Redshift and Google BigQuery
Data Lake
A Data Lake addresses the limitations of a data warehouse by supporting both structured and unstructured data and, crucially, by decoupling storage and compute, allowing independent scaling as workloads increase. Additionally, unlike a data warehouse where data formats are fixed, a data lake stores data in an open format, enabling the use of various tools for data access and analysis. Unfortunately, the decoupling of storage and compute means that many advantages such as ACID transactions and indices are absent, resulting in poor performance. Examples: AmazonS3 and Google Cloud Storage
Data Lakehouse
Data Lakehouse is an architectural approach to data management that leverages a combination of technologies and processes to combine the best features of data warehouses and data lakes. It provides an ideal platform to store, manage, and analyze data at scale. A critical component of this architecture is the table format, a method of structuring a dataset’s files to present them as a unified “table.” From the user’s perspective, it can be defined as the answer to the question “what data is in this table?” Another critical component of this architecture is a data catalog. Examples of Data Lakehouse solutions: AWS Lake Formation and Delta Lake by Databricks.
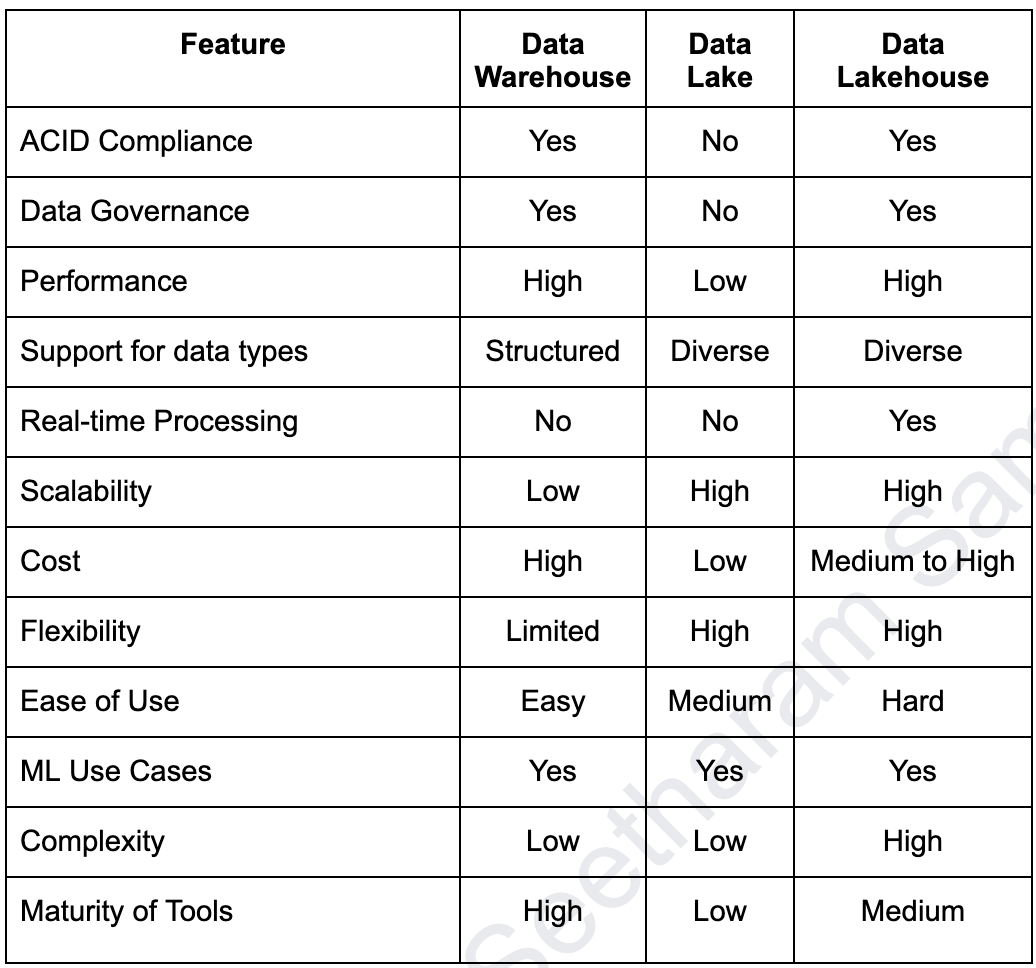
Comparison of Data Architectures
The following table summarizes the difference between the three data storage and management architectures:
Two-Tier Data Architecture
In my previous job, around 2021-2022, we implemented a Two-tier data architecture as shown in the diagram below. At that time, Data Lakehouse architectures were already gaining popularity and was an option. However, the main software stack needed refactoring and hence those improvements took priority over modernizing the Data architecture.
In this architecture, the data from various sources is ingested, processed, and utilized by different teams. It begins with data sources, including structured data from SQL/NoSQL databases, semi-structured data (XML, JSON, RDF), and unstructured data (flat text, images). Structured data from both SQL and NoSQL databases undergo change data capture (CDC) using Debezium and Kafka Connect, which streams the data in real-time into a Data Lake. The Data Lake serves as a central repository, storing all types of raw data in a scalable manner.
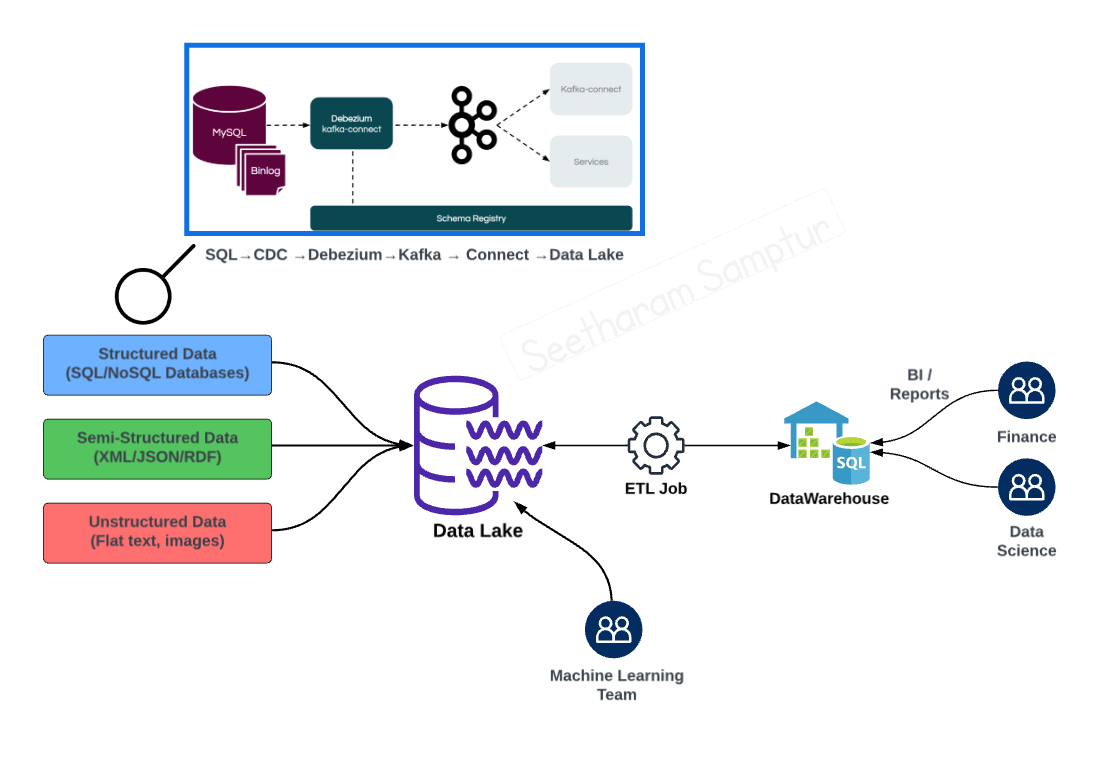
Subsequently, an ETL (Extract, Transform, Load) job processes the data from the Data Lake, transforming it into a suitable format and loading it into a Data Warehouse. The Data Warehouse supports complex queries and analysis, providing refined data for business intelligence (BI) and reporting by finance and data science teams. Additionally, the Machine Learning team accessed raw data from the Data Lake and had their own ETL jobs data cleansing before using it for advanced analytics and model training. In this architecture, data is often classified into Bronze, Silver, and Gold tiers. Bronze data refers to raw, unprocessed data directly ingested into the Data Lake from various sources. Silver data is the cleaned and transformed data, processed and organized for better usability. Gold data represents the highest quality, fully refined data ready for advanced analytics, business intelligence, and reporting.
Data Lakehouse using Apache Iceberg
In my recent project, we are dealing with lots of parquet files and need a mechanism to make it easy for our internal customers for operations and analytics purposes. All the data resides in cloud storage and we want to minimize costs by not having to copy this data to different systems. We are evaluating Iceberg, especially, after it got all the attention recently with Databricks acquiring Tabular, to bolster its capabilities in data lakehouse architecture.
Apache Iceberg is a table format for defining a table as a canonical list of files, rather than as a list of directories and subdirectories. It provides a specification for how metadata should be written across several files in a data lakehouse. To support this standard, it includes numerous libraries to assist users and compute engines in working with the format. Please refer to the Apache Iceberg web site for more information.

The diagram depicts a Data Lakehouse Architecture where multiple tools and technologies (DBeaver, Trino, Nessie, Iceberg, Apache Spark, and Cloud Storage) work together to provide a unified, high-performance platform for storing, managing, and querying large datasets. This architecture leverages the flexibility of data lakes with the reliability and performance of data warehouses.
With the help of Dremio’s Alex Merced’s Apache Iceberg 101 videos, it only took a weekend to set up a proof of concept. However, productizing it will take much longer due to the numerous design choices required and the inherent challenges of setting up and maintaining any open-source solution. One critical design decision is choosing the right catalog; it plays a crucial role in identifying and managing data from various sources. There are many catalogs including Hive Metastore, Hadoop, REST, Nessie, and AWS Glue and given my constraints, I decided to use the Nessie catalog. I am eagerly awaiting Snowflake's open-sourcing of their catalog solution, code-named Polaris, to see if it offers easier setup and maintenance.
Another challenge is creating Iceberg tables through schema inference. Tabular provides a hassle-free file ingestion to Iceberg tables but it’s not open-source. For now, I plan to write a few PySpark jobs to infer the schema and create Iceberg tables. Unfortunately, this process isn’t completely automated because one must explicitly specify the partitioning column during Iceberg table creation.
I am using Apache Trino, a distributed SQL query engine that integrates seamlessly with both Nessie and Iceberg to access the metadata and data required for queries.
Conclusion
In this post, I provided an overview of different data architectures, including the two-tier data architecture and a simple Data Lakehouse implementation using Apache Iceberg. I’ve only covered the tip of the Iceberg, and there are many more features to explore, such as integrating streaming data in real-time. If you ask me what the best option is, my response would be, “It depends.” I recommend starting with your specific problem, identifying the necessary features for the solution, deciding between buying and building based on your budget, and finally considering the long-term maintenance and scalability of your chosen architecture. Additionally, evaluate the community support and documentation available for any open-source solutions, as these factors can significantly impact the success and sustainability of your implementation.