
The Agentic AI Tax
The hidden cost of letting AI agents think in loops


Introduction
It’s that time of year when everyone in the US is getting ready to file their taxes. So I figured it’s a good time to talk about another tax you’re paying: the Agentic AI Tax.
By now, most of you have heard about OpenClaw and similar tools that have spawned alongside it. These, along with coding agents like Claude Code, Cursor, and Kiro, are being used to build impressive things at lightning speed. But right after watching them build something magical, you open your billing dashboard and discover a number that makes your head spin.
Welcome to the Agentic AI Tax.
It’s the hidden cost of letting AI systems think in loops, retry on failure, and carry enormous context windows through multi-step tasks. And if you’re building or using agentic AI tools, you’re almost certainly paying more of it than you need to.
Why Agents Are Token-Hungry
To understand the tax, you need to understand how LLM pricing works and how agentic AI exploits it in the worst possible way.
LLM providers bill on two things: input tokens (what you send) and output tokens (what the model generates). The asymmetry matters - output tokens typically cost 3-5x more than input. With Claude Sonnet 4, you’re paying $3 per million input tokens but $15 per million output tokens. With Opus 4, those numbers jump to $15 and $75.
With a simple chatbot, this is manageable. One round-trip. Tokens in, tokens out. Predictable.
An agentic workflow is a completely different animal. The AI calls a tool, reads the result, decides what to do next, calls another tool, reconsiders, maybe retries all in a loop. Each iteration sends the entire conversation history back to the model. Your system prompt, all previous tool calls, all previous results, every single time.
Now layer the pricing asymmetry on top of that loop. Agents are chatty as they reason through decisions, generate verbose tool calls, and produce explanations nobody asked for. All of that expensive output gets recycled back as input on the next step, where you pay for it again. The agent’s reasoning from step three becomes part of the input bill for steps four through twenty.
The math gets ugly fast. Say your system prompt is 2,000 tokens and your agent takes 15 steps. You’re paying for that system prompt 15 times. Each step adds tool results and model reasoning, so your context balloons from 3,000 tokens on step one to 5,000 by step five to over 16,000 by step fifteen. Most of it is stuff the model has already seen, and the most expensive tokens (output) are being fed back and re-read on every subsequent step.
This is the core of the Agentic AI Tax: redundancy and asymmetry, compounding at scale. And that’s assuming everything goes smoothly. In practice, agents also burn tokens on retries when a tool call fails or returns something unexpected, bloated API responses that include far more data than the agent actually needs, and system prompts stuffed with instructions irrelevant to the current step. Each of these multiplies the problem further.
Key Strategies to Lower Your Agentic AI Tax
The good news: this is an engineering problem, and engineering problems have solutions. Here are the strategies that actually move the needle.
Prompt Caching
Both Anthropic and OpenAI now support prompt caching at the API level. I’m more familiar with Amazon Bedrock where prompt caching is an optional feature that stores reusable portions of your prompt in a cache. Instead of reprocessing the same context on every request, you define cache checkpoints that mark the static content you want preserved, and subsequent calls read from the cache at a reduced token rate rather than recomputing those tokens.
The key to getting the most out of this is structuring your prompts so the cacheable content comes first and stays stable. Place your system prompt, tool definitions, and any static reference material at the top. Keep the dynamic, changing parts like conversation history and current task context at the end. The more of your prompt that remains identical between calls, the more you save.
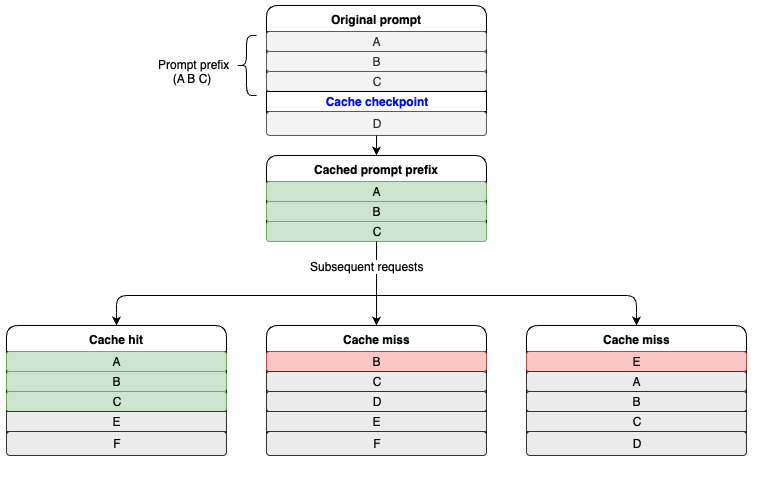
Source: Prompt Caching on Amazon Bedrock
This is particularly powerful for large-scale migration workloads such as language or framework upgrades across many packages. The migration instructions, conventions, style guides, and API mappings remain the same from one package to the next. All of that static guidance gets cached, while only the specific source code changes between requests. When you’re processing hundreds or thousands of files through the same transformation, you pay the full input token cost once and read it back at a fraction of the price for every subsequent call.
If you’re building agentic systems and you haven’t implemented prompt caching yet, stop reading and go do it. Seriously. It’s the lowest-effort, highest-impact optimization available.
Prompt Compression
As agentic AI systems scale to process thousands of support tickets, log files, and RAG-injected documents, context bloat becomes a real problem. Batches routinely exceed 100K tokens, inflating latency and diluting the signal your LLM needs to reason over.
The idea behind prompt compression is straightforward: reduce token count while preserving semantic meaning. Unlike truncation or summarization, which lose information, compression identifies and removes tokens that contribute least to the prompt’s meaning. You get a shorter input that carries the same essential information.
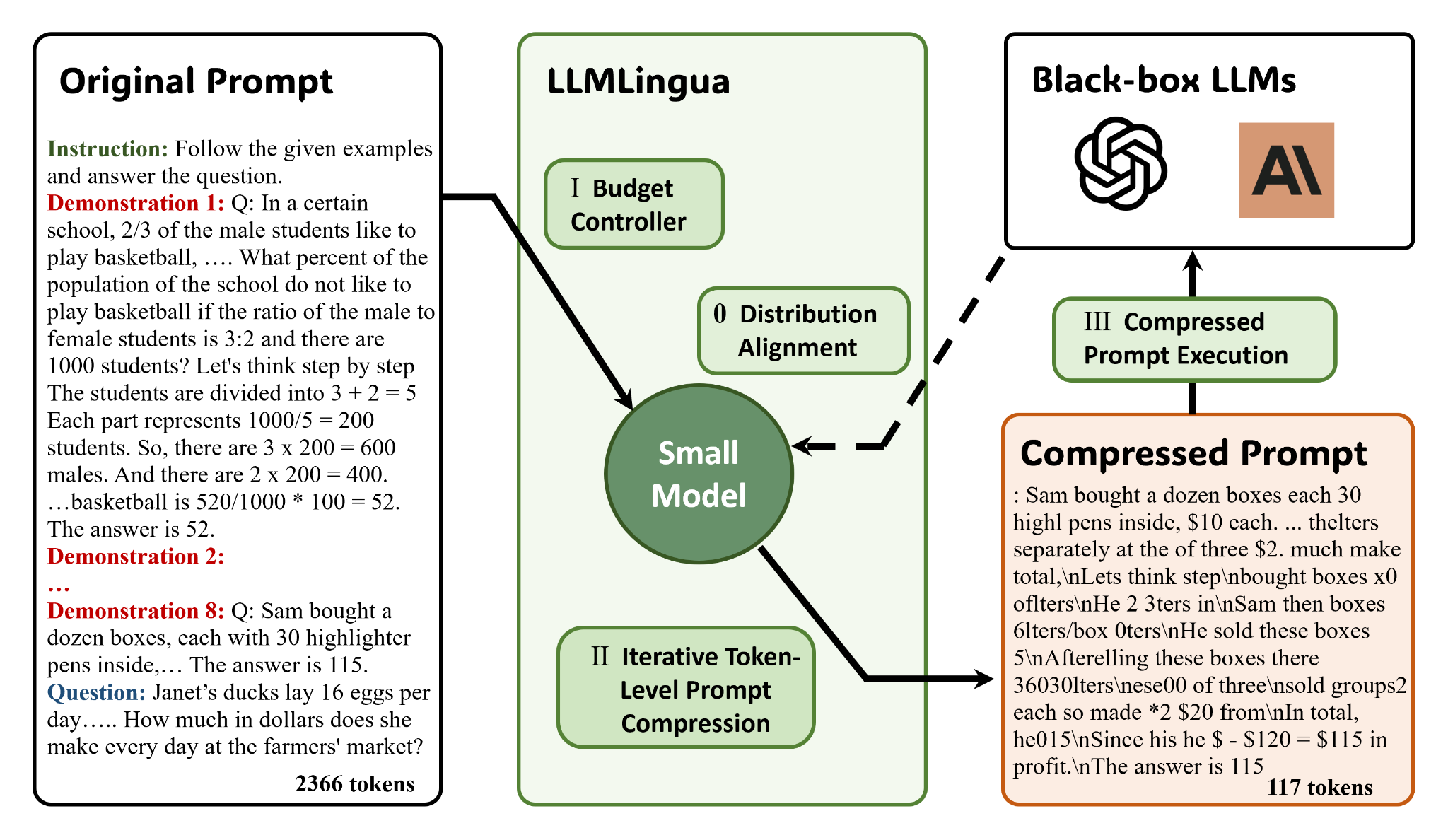
LLMLingua-2, developed by Microsoft Research, takes a clever approach to this. Instead of measuring how “surprising” each token is to a language model, it learns token importance directly from GPT-4 through a process called data distillation. It works in three steps:
GPT-4 annotates which tokens in a prompt are essential versus removable, creating a labeled dataset where each token is marked “keep” or “drop.”
A small encoder model (XLM-RoBERTa or mBERT) is trained on this labeled data to classify tokens, learning to predict which ones to keep.
At runtime, the trained model scores each token and removes those below a configurable threshold based on your target compression rate.
The key insight is that a small, fast model learns what GPT-4 considers important, then applies that knowledge at a fraction of the cost and latency. According to benchmarks, the result is roughly 50% token reduction while preserving 8 to 9 out of 10 in response quality, cutting API costs by 40-46%.
One important caveat: compression shines on verbose, unstructured text like tickets and logs, but should be avoided on code, precise numerical data, and system instructions where every token carries weight. I’m still experimenting, but worth investigating for your high-volume workloads.
Recursive Summarization
Here’s a pattern that bites almost every agentic system: the conversation history grows without bound.
Your agent completes step one, step two, step three, and by step twenty, it’s carrying the full detail of every previous step in its context window. Most of that detail is irrelevant to the current decision. The agent doesn’t need to remember the exact JSON response from step three to make a good decision at step twenty. It needs to know what happened and what was decided. I wrote about why this happens in a previous post, but the short version is that the problem isn’t context capacity but comprehension.
Recursive summarization solves this. Periodically, every N steps or when the context hits a size threshold, you pause the loop and ask the model to summarize the conversation so far. The next time a summary is needed, the model combines the previous summary with whatever new context has accumulated, producing an updated version. Each summary builds on the last rather than re-processing everything from scratch.
A good summary captures decisions made, key findings, current state, and remaining goals in a fraction of the tokens. You go from 8,000 tokens of raw history down to 800 tokens of distilled context. One counterintuitive finding from a 2023 research paper: recursively generated summaries can actually outperform human-annotated ground-truth memory as context for the model. Fragmented notes turn out to be harder for LLMs to digest than a coherent, naturally written summary. The model works better when its memory reads like something it would have written itself.
The broader point: teaching your agent to maintain its own distilled memory beats simply expanding context windows or bolting on a retriever. You trade some granularity for compression, but iterative refinement keeps the working context lean while preserving what matters.
It’s worth noting how this differs from prompt compression. Compression strips low-value tokens from a block of text while keeping the same content and structure intact. Recursive summarization is a fundamentally different operation - it reads the content, makes judgment calls about what matters, and rewrites it from scratch. Compression is like editing a book to remove filler words while keeping every chapter. Recursive summarization is reading the whole book and writing the CliffsNotes. In practice, they complement each other: use compression to trim verbose inputs like tool outputs and RAG documents, and use recursive summarization to manage the growing conversation history.
Model Routing
Not every step in an agentic workflow needs your most powerful (and expensive) model.
The planning step, deciding what to do next, might need Claude Opus or GPT-4. But the extraction step, pulling a specific value from a JSON blob, probably works fine with Haiku or Sonnet at a fraction of the cost.
Smart model routing means analyzing each step in your agent’s workflow and assigning the cheapest model that can handle it reliably. Services like Amazon Bedrock, Azure AI, or libraries like LiteLLM make this straightforward as they help you route to different models through a single API by swapping a model ID, no need to maintain separate clients for each provider.
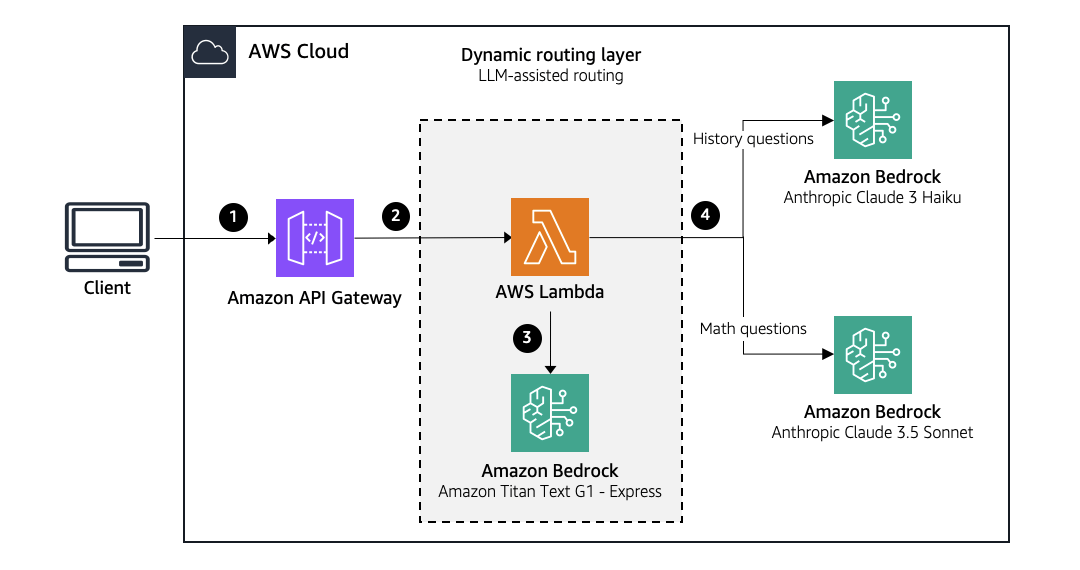
Source: Model Routing on AWS
This does require more engineering effort than the other strategies. You need to classify step types, test that your cheaper models hold up on the tasks you’re routing to them, and handle fallbacks when a lighter model isn’t cutting it. But for high-volume agentic workloads, the ROI is substantial. The principle is simple: use your expensive models for steps that require reasoning, and cheap models for everything else.
Conclusion
Agentic AI is genuinely powerful. The ability to let an AI system plan, execute, and iterate is a step change from static prompt-response interactions. But that power comes with a cost structure that can catch teams off guard.

This isn’t a theoretical problem. On a recent episode of the All-In Podcast, Jason Calacanis revealed he was spending $300 per day per Claude agent through API usage, even though the agent was only operating at 10-20% capacity. That’s roughly $100K per year per agent. Chamath Palihapitiya responded by asking his team a question every engineering leader should be asking right now: “What’s the token budget for our best devs?” Mark Cuban took it further, calling this the smartest counter he’d seen to AI taking over jobs in the short term. His math was blunt: if eight Claude agents at $300/day plus $200/day in dev and maintenance costs are doing the work of one employee at $1,200/day fully loaded, that’s $2,600 versus $1,200. The agents need to be more than 2x as productive just to break even.
The strategies in this post are how you shift that equation. The Agentic AI Tax isn’t a reason to avoid agentic workflows. It’s a reason to engineer them thoughtfully. Start with prompt caching (easy, high impact), audit your prompt sizes and tool outputs, compressing verbose inputs like logs and RAG documents (medium effort, medium impact), implement recursive summarization for long-running tasks (higher effort, high impact for the right workloads), and consider model routing if you’re operating at scale. In our own work, we’ve used prompt caching on large-scale migration projects and are exploring prompt compression for context-heavy use cases involving log files, tickets, and documents. As for recursive summarization and model routing, if you’re using coding agents like Kiro or Claude Code, you’re likely already benefiting from both as most agents summarize on hitting context thresholds and route simpler tasks to cheaper models under the hood.
The teams that figure this out early won’t just save money. They’ll be able to run more ambitious agents, longer workflows, and more complex tasks, because they won’t hit a cost ceiling that forces them to scale back.
The tax is real. But like any tax, the smart move isn’t to stop earning. It’s to optimize.
Thanks for highlighting the LLMlingua model. Text files will forever be larger than LLM contexts. Strategies like LLMLingua can help compress text files in such a way that information is not lost so that LLMs can summarize without running out of context.
Although the compressed text is still human readable, do you think it may be preferable to save the original text for human readability i.e whether 2 versions of text should be saved, one for humans and another for LLMs.