
What Memory Frameworks Forget
What it takes to ship agent memory


Source: https://www.forbes.com/sites/williamhaseltine/2024/08/02/short-vs-long-term-memory-why-you-remember-your-birthday-but-not-where-you-left-your-keys/
Introduction
In the last two posts, I argued that coding agents don’t need a persistent memory layer. Their context lives in the repository, and what little they need beyond that is ephemeral session state. There are exceptions even for coding work, like team memory that needs to persist across projects. But Domain Agents are different. Memory isn’t an exception for them. It’s the core of how they work.
By Domain Agents, I mean AI systems that maintain a long-term relationship with a specific user or organization, often within a vertical like security, finance, or healthcare. They range from customer-facing chatbots to autonomous agents running multi-step workflows. What unifies them isn’t the domain. It’s the continuity. These agents are expected to remember who they’re working with across sessions, learn preferences over time, and accumulate organizational context that no single conversation can provide.
For these agents, the question isn’t whether memory matters. It clearly does. The question is how to build it. There’s no shortage of frameworks. Mem0 and A-Mem are two recent academic proposals, and commercial offerings like Zep and LangMem add more. But choosing a framework is the easy part.
What memory actually has to do
Let’s first discuss the expectations from a memory system before delving into the different options that we could consider. Every memory system solves four problems: Extraction, Storing, Retrieving and Evolution.
Extract. When a conversation happens, the system has to separate signal from noise. The signal sits in a few salient facts: a stated preference, a decision made, a constraint mentioned. This is the same problem I covered in my earlier post, The Missing Layer in Code Reviews. The mechanics are similar even though the artifact is different: an LLM reads the conversation and produces candidate memories.
Store. Once extracted, memories need a home. The simplest format is a flat list of natural-language facts. A more structured variant is the Zettelkasten approach, where each memory is an atomic note linked to related notes, with structure emerging from the links rather than imposed by a schema. Graph databases push further, modeling entities and relationships explicitly.
Retrieve. At query time, the system has to surface the small subset of memories that matter. Semantic similarity is the common approach, often combined with reranking or relational traversal.
Evolve. Memories aren’t static. Preferences change, decisions get reversed, facts go stale. The system has to decide whether to overwrite, version, mark obsolete, or flag for review. Getting this right is key to ensuring the memory is stable.
These four operations sound simple. The frameworks differ in how they answer the harder policy questions underneath: what to extract, how to scope, and when to overwrite.
Mem0: explicit operations on flat memory
Mem0 takes a straightforward approach. Extract facts from conversations as natural language, store them flat, and retrieve them later by semantic similarity. No graphs, no schemas, just a list of facts attached to a user.
The pipeline has two phases. The extraction phase is triggered by the application that hosts the agent. After each user-agent exchange, the application passes the message pair to Mem0, which runs extraction in the background. Mem0 is a passive library. It depends on the host application to decide what conversations get processed and when. An LLM reads the exchange alongside recent conversation context and produces candidate facts worth remembering. Most exchanges produce nothing. Some produce one or two facts.
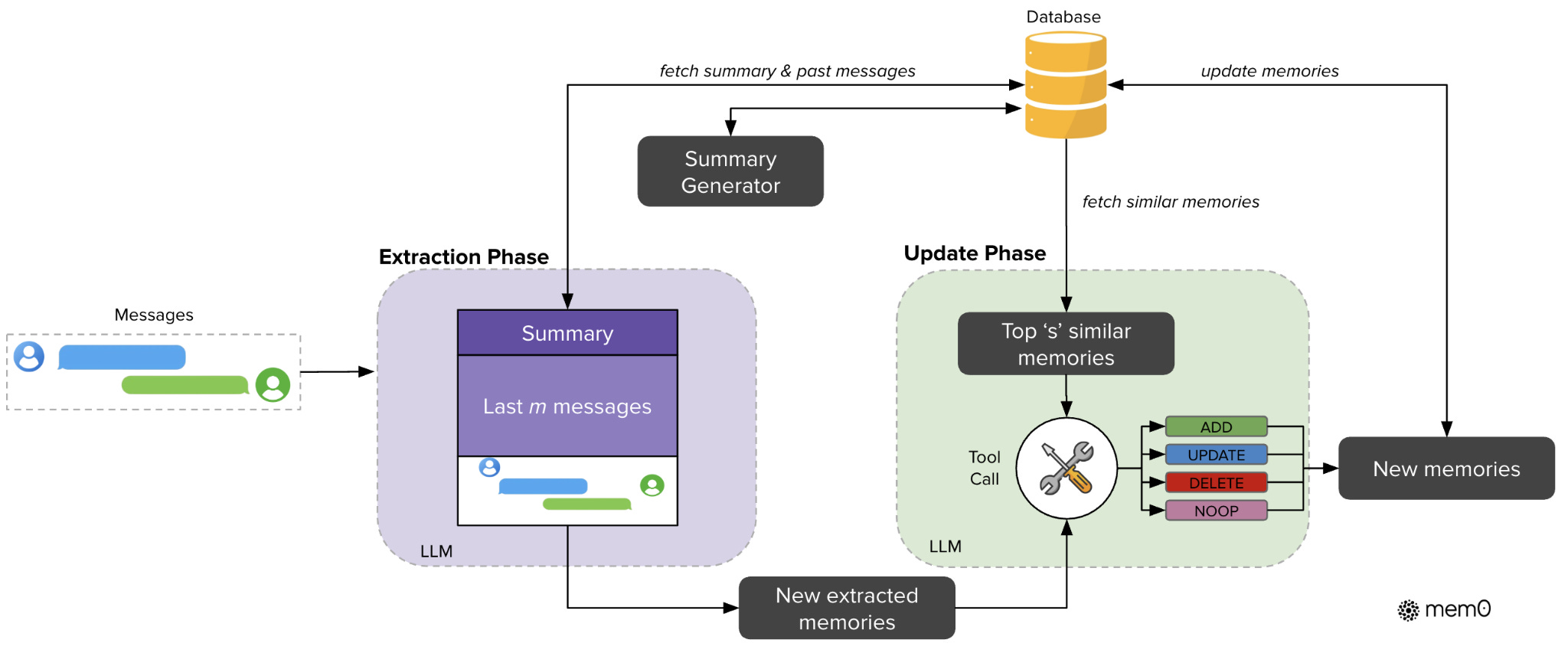
Source: Mem0 paper: https://arxiv.org/html/2504.19413v1
The update phase then decides what to do with each candidate. For every new fact, the system retrieves the most similar existing memories and asks an LLM to pick one of four explicit operations. ADD creates a new memory. UPDATE augments an existing one with new information. DELETE removes a memory contradicted by the new fact. NOOP leaves things alone.
The explicit operations matter and every change to memory is auditable. You can look at the history and see exactly what was added, what was changed, what was removed. Note that these operations execute automatically. The host application calls Mem0 once with the new exchange, and Mem0 runs extraction, decides operations, and writes them in a single pipeline. There’s no built-in approval step. If you want human validation before a memory gets deleted, you build it yourself.
Mem0 also has a variant called Mem0g, which adds a graph layer on top. Entities become nodes, relationships become edges, and the system can answer queries that require traversing connections between memories. Mem0g costs more in storage and latency but does better on temporal reasoning, the kind of question that asks when something happened or what came before what.
Beyond the Mechanics: Where Frameworks Fail
While the frameworks remember a lot, they tend to forget the parts that matter the most.
Scoping. Mem0 and A-Mem, another memory framework, both pool everything into one bucket. This works fine when memory is per-user, since everything belongs to that user anyway. For team or organizational memory, it breaks down. Teams work on multiple projects, and pooling everything together blurs the boundaries. This is fixable, but you have to build the scoping layer yourself.
Consent. Users don’t see what’s being extracted. They can’t approve a new memory before it’s stored, correct one that misrepresents them, or selectively delete memories that no longer apply. The extraction LLM decides what’s salient. The user finds out later by observing the agent’s behavior.
Evidence quality. A casual mention is treated the same as a deliberate statement. Tell the system in January you’re allergic to peanuts, then in June say “I had peanut butter and felt fine.” Mem0 will happily DELETE the allergy based on one offhand comment. There’s no weighting of evidence, no caution around safety-critical facts.
Auditability. Mem0’s operations are visible but destructive. A DELETE loses the history of what used to be true. A-Mem takes the opposite approach, drawing on the Zettelkasten method to let memories evolve through reinterpretation. Older memories get reshaped as new ones arrive. Neither approach gives you what you actually want: a record of what was believed when, and why.
The frameworks handle the mechanics. The harder questions, like what’s worth remembering and when to use it, fall to your integration code and to the agent at runtime.
What production memory actually requires
The gap that memory frameworks leave for you to fill is captured well in a recent AWS and TrendMicro post. TrendMicro recently shipped a company-wise memory architecture for their AI chatbot using Mem0, in collaboration with AWS. What stands out is that Mem0 is one component among six. Neptune handles the knowledge graph, OpenSearch handles vector search, Bedrock orchestrates the LLM calls and reranking, and a human-in-the-loop layer sits on top of all of it.
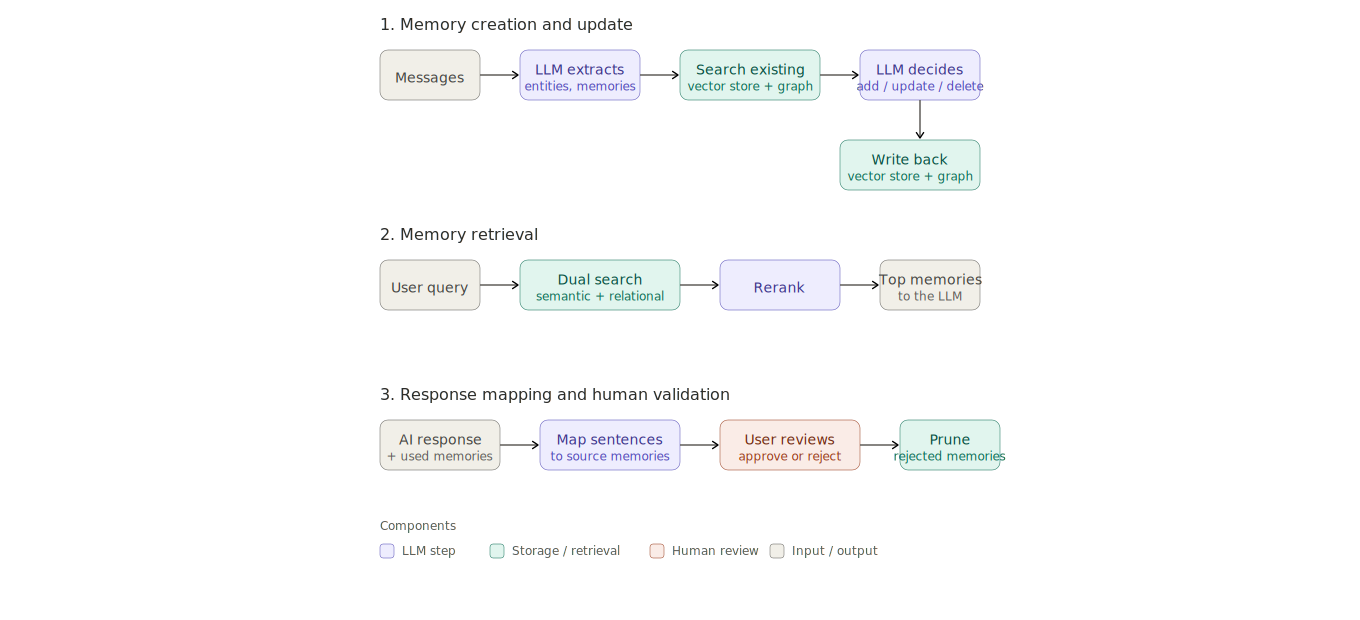
That last piece matters most. The human-in-the-loop validation layer handles exactly the problems the framework leaves unresolved. Users can see what’s being remembered, approve or reject mappings, and prevent low-quality memories from polluting future retrievals. The striking part of the architecture isn’t that TrendMicro used Mem0. It’s that Mem0 alone was insufficient for production use.
The lesson is that production memory is architectural, not library-level. Even sophisticated teams assemble multiple systems for extraction, retrieval, validation, orchestration, and governance rather than relying on a single framework. The framework is the start of the work, not the end.
Conclusion
Agents become more useful when experience compounds across time instead of resetting every session. One way to achieve that is by giving your domain agent a memory layer. It’s a system that gets better at its job as it learns who it’s working with, what’s been tried, what worked, and what didn’t.
I’ve seen two good use cases where memory is essential. One is an autonomous DevOps agent that tracks issues and tickets across time. It can triage faster and propose better fixes because it remembers what worked the last time a similar problem came through. The second is the AWS and TrendMicro example from earlier: a team’s accumulated knowledge captured from conversations rather than from a curated wiki that no one updates.
For these systems, frameworks like Mem0, Mem0g, or A-Mem provide the foundation, but not the full solution. Production memory still requires scoping policies, validation layers, governance controls, and supporting infrastructure for retrieval and evolution. The difficult part isn’t storing memories. It’s deciding which memories deserve to shape future behavior.