
Demystifying Agent Harness
Beyond the Execution Loop


Introduction
In early 2025, as teams across the industry were experimenting with different ways to apply AI, I wrote a simple command line tool wrapped around an LLM called WISH, short for Workflow Infused SHell. My goal on the builder experience team was straightforward, which was to ship tools that helped developers move fast, and with WISH you could execute complex SDLC workflows with a single command. I used it constantly, yet most developers were still primarily experiencing AI through autocomplete and chat interfaces..
As autonomous coding agents exploded onto the scene over the following months, I let go of WISH as a product and moved with the current of the industry, experimenting, building, and leaving behind a trail of blog posts about what worked and what did not. Looking back, each post explored a different layer of the same system. What appeared to be separate discussions about MCP, memory, context engineering, skills, and evaluation were actually pieces of a larger architecture that the industry now increasingly recognizes as the Agent Harness. In this post I am pulling those scattered threads together to deconstruct exactly what an Agent Harness is, and why it has become the defining architecture of modern AI engineering.
The Agent Harness
We started with ChatGPT, a simple interface bolted onto a stateless Large Language Model. But engineering isn’t just about chatting and we needed applications that could programmatically interact with an LLM to execute tasks and thus, the Agent was born. As those tasks grew more complex, the models needed access to live data and external systems beyond their training weights. For many scoped, repetitive use cases, a basic loop with a few tools is enough. I coined the term Agentlet to describe these setups, an LLM wrapped in a very thin, single-purpose harness.
Agentlets work beautifully for simple automation, yet robust autonomous systems demand far more than a handful of tools. They need context management, along with short-term working memory to track a conversation and long-term state to remember past decisions.The broader infrastructure that supplies all of these capabilities, from the loop itself to the tools and the layers of memory, is what we now call the Agent Harness. Tools such as Kiro CLI, Claude Code, and Gemini CLI are shipping increasingly capable harnesses today, each one constantly adding features in the race to win over developers, and we are even beginning to see advanced harnesses like Hermes that learn over time and generate new skills dynamically.
To put it simply, if the LLM is the brain, then the Agent Harness is the entire body that carries it through the world.
The Loop
Strip away every layer of sophistication a modern harness adds, and what remains at the center is a single loop you cannot remove without the agent ceasing to be an agent. The model perceives the current state, decides what to do next, acts by calling a tool, and observes the result, and the cycle repeats until the goal is reached or the agent runs out of room. Everything else in the harness, all the memory and context discipline and guardrails we will get to, exists only to make this loop run longer and with better judgment.
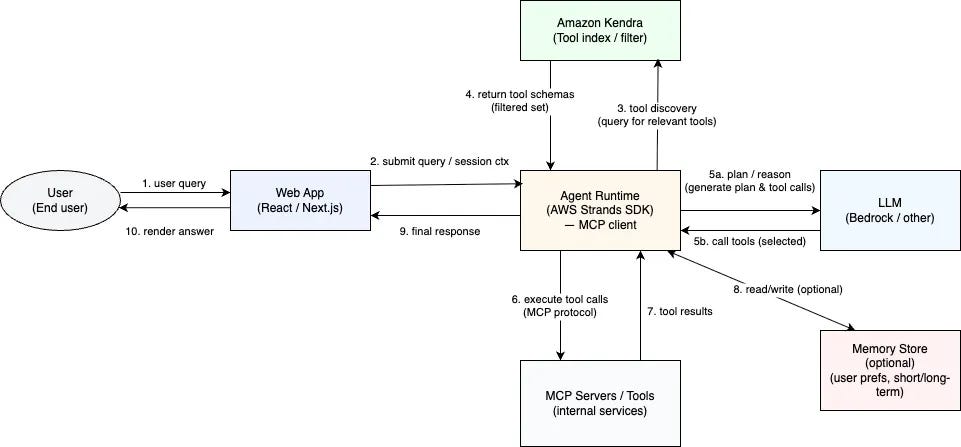
In my post, The Age of Agentic AI, I walked through a connected enterprise assistant on the Strands SDK whose job came down to a few repeating steps, gathering the right information, forming a plan, breaking the work into sub tasks, executing, and adapting based on what came back. That was WISH now reasoning over internal systems through MCP rather than executing predefined workflows from a terminal. It is held together through ReAct, which interleaves thinking with acting so that each tool call is chosen in light of the last one rather than planned blindly up front. None of this was new even then, which was the point, because I had once written about the loop’s strategic ancestor, the OODA loop of Observe, Orient, Decide, and Act, and the resemblance is no coincidence, since both describe an agent of any kind folding new observations back into its next move.
What I could not see at the time was that this loop was only the engine, and an engine still needs a chassis and a steering system before it can safely take you anywhere.
MCP Tools & Skills
A loop that can only think remains inert until tools allow it to reach out and manipulate the world by searching for information or running scripts. The fundamental challenge was how agents connect to these tools since wiring them directly produced the exact mess of dropped context and exposed security I warned about in Are AI Agents the New Microservices. The industry solved this by converging on the Model Context Protocol as an open standard that gives the harness a consistent way to discover and orchestrate tools behind a single interface. While these protocol tools operate outside the model to connect it to the external world, Skills operate inside its reasoning to teach it exactly how and when to utilize those capabilities. Skills simultaneously keep the context window lean because an evaluating agent only sees their compact front-matter instead of the full tool definition. Drawing from lessons learned during the microservices era, the harness stays much healthier when capabilities arrive as sharply scoped units instead of one monolithic server acting as a cluttered multipurpose utility.
Context Matters
Everything the loop does competes for one scarce resource, the context window, the working memory holding the system prompt, the conversation so far, the tool definitions, and whatever gets retrieved. The instinct is to assume a bigger window solves this, but in Lost in Context I dug into why that misleads, since the lost in the middle effect shows models reliably use information at the start and end while underusing whatever sits in the middle. The problem was never capacity but comprehension, so good context engineering is curation rather than accumulation: feed the loop only what the step needs, select tools dynamically, and retrieve the rest on demand. This discipline also shows up in billing, because as I argued in The Agentic AI Tax, the loop resends the whole history every step, so prompt caching and recursive summarization keep the context both lean and cheap.
Memory: short term, then long term
I added short-term memory to the loop first. It is a transient scratchpad for immediate actions and failures. As I argued in Coding Agents Do Not Need Personal Memory, this state is ephemeral. It belongs only in the active context window. The true durable context already lives in your repository. It lives inside your AGENTS.md files and Architectural Decision Records (ADRs). The scratchpad dies when the task ends, but long-term memory transforms a simple loop into a true Agent Harness. This state survives across runs to compound value over time. It remembers past successes and failures. However, as I noted in What Memory Frameworks Forget, this promise is deceptively expensive. You cannot just dump chat logs into a vector database. You must extract salient facts, retrieve the exact subset, and prune stale data. Frameworks like Mem0 only provide the basic plumbing. Deciding the strict policy of which memories shape future behavior is the real engineering.
Control and Reliability
An execution loop that never checks its work or recovers from a bad tool call is a liability rather than true autonomy. The harness provides the critical machinery to keep this loop honest by enforcing sensible stopping conditions, retrying transient failures, and applying strict behavioral guardrails. As I argued in The Deming Way to Build Responsible AI, quality must be engineered directly into the process by treating guardrails as foundational design instead of retroactive patches. Agentic loops frequently skip the critical study step and create the exact production fragility I described in Fast Code, Fragile Systems where impressive demos inevitably buckle under actual load. Evals earn their place in the harness because a steady regimen of automated evaluation using human reviewers or an LLM judge remains the only reliable way to measure actual improvement. Without folding this feedback loop back into the underlying system, the agent simply runs forward without any structural accountability.
Conclusion
Looking back, WISH was only the first piece of a much larger system. Over the following 18 months, I wrote about MCP, memory, context engineering, RAG, and evaluation as separate topics. They were all different facets of the same architecture.
The industry’s first wave of innovation focused on models. Increasingly, differentiation is shifting from models to harnesses. Foundation models provide the intelligence, but the harness determines how effectively that intelligence can perceive, act, remember, recover, and improve over time. The winning play remains the same: keep the harness thin and only strengthen it where additional capability genuinely earns its keep.
Thanks to my friend Sam for pushing me to connect these ideas into a single framework.
What does your favorite agent harness look like? Which layer did you build first?
https://arxiv.org/pdf/2605.18747 - survey paper